
Enrichissement sémantique et gestion sécurisée des documents dématérialisés
Responsable LIMOS : LAFOURCADE PascalCoordinateur : Barra
Début du projet : 1 octobre 2016 - Fin du projet : 30 septembre 2019
Projet piloté par le LIMOS
Après la révolution de l’imprimerie initiée par Gutenberg, le XXIème siècle est celui de la révolution numérique. L’essor des technologies du numériques de manière générale, et celui de l’informatique en particulier, a provoqué une mutation profonde des sociétés modernes qui se traduit par plusieurs aspects telle qu’une mise en réseau à l’échelle mondiale et de nouvelles formes de communication mais aussi, sur les plans industriel et commercial, par une automatisation accrue des processus métier et par une dématérialisation de plus en plus importante des services et des informations.
Aujourd’hui, la plupart des échanges et des transactions sont automatisées et un très grand nombre de services est disponible sous forme électronique. Ce phénomène de dématérialisation s’accompagne par une expansion de la numérisation, en tant que procédé de conversion des informations d’un support quelconque (e.g., papier) en données numériques. A l’heure actuelle, une grande masse de données qui se trouve encore sous forme papier, comme des factures, des bulletins de paies, des analyses médicales, etc, sont scannés et leurs images stockées sur des supports informatiques, souvent archivées auprès d'un «tiers de confiance». Se pose alors des questions essentielles liées à la gestion de ce type de données et à leur intégration dans les applications métiers des entreprises. Très souvent, la forme brute de ces données rend très difficile, voire impossible, la manipulation de leurs contenus de manière automatique
par des programmes informatiques. Par conséquence, de nombreux traitements sur ces données, comme par exemple la vérification des données contenues dans une image de document scanné, sont la plupart du temps réalisés de manière manuelle. Ce projet s’inscrit dans la problématique générale de la dématérialisation des documents et vise à développer des techniques qui permettent de faciliter la gestion et l’exploitation de documents dématérialisés. Le projet est porté par deux laboratoires Universitaires associés au CNRS, le laboratoire d’informatique ( LIMOS) et le laboratoire de psychologie cognitive (LAPSCO), en liaison avec un consortium d’entreprises. Du point de vue scientifique, le projet s’intéresse à deux questions fondamentales qui sont
illustrées dans la figure ci-dessous:
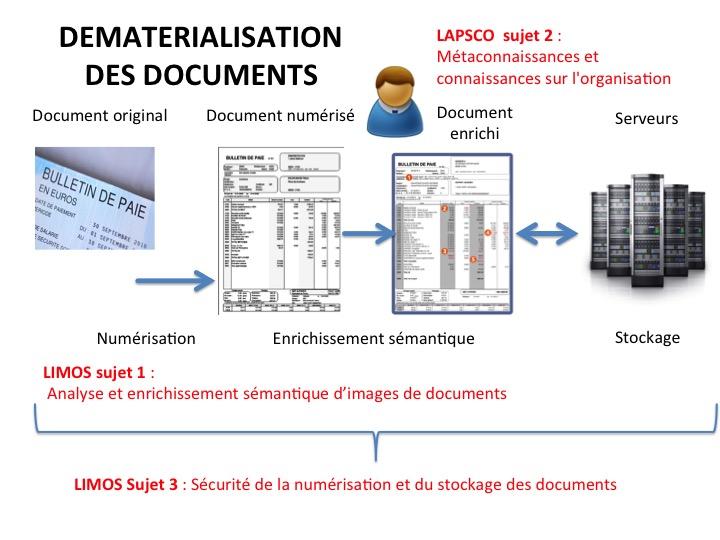
● l’enrichissement sémantique des images de documents. Il s’agit ici d’être capable d’analyser une image de document de manière à pouvoir interpréter son contenu et en extraire de la sémantique. Le programme de recherche envisagé s’appuie à la fois sur des approches techniques d’analyse d’images et d’apprentissage mais explorera aussi les aspects cognitifs liés à l’exploitation des métaconnaissances textuelles dans le processus d’enrichissement sémantique,
● le stockage et la gestion de documents numérisés. Il s’agit de s’intéresser à des questions liés à la fiabilité, notamment la sécurité, et à l’efficacité des modèles
physiques de stockage.
Du point de vue opérationnel, le projet est structuré autour de trois sujets de recherche complémentaires :
1. Analyse et enrichissement sémantique d’images de documents (LIMOS). L’objectif est de développer des techniques qui permettent de dématérialiser et
d’analyser un ensemble de documents. Ce processus consiste à les « reconnaître » et les traiter (filtrage, données manquantes, données erronées) afin de pouvoir les interpréter (extraction d’information, analyse de données, enrichissement sémantique) en fonction du contexte métier. Les applications de ce travail peuvent concerner la réduction des erreurs de détection et de traitement, l’agrégation interne (à l’entreprise) et externe (Web, réseaux sociaux) de données similaires.
2. Métaconnaissances et connaissances de l’organisation des documents pour leur compréhension (LAPSCO). L'analyse de documents dématérialisés pourrait
permettre d'identifier les informations pertinentes ce qui augmenterait la fiabilité de l'extraction. La pertinence pourrait être identifiée non seulement grâce à des éléments d'analyse de la sémantique des informations (le contenu ... les informations importantes) mais aussi à partir des connaissances sur l'organisation d’un texte, sa structuration etc. (on parle alors de métaconnaissances textuelles).
3. Sécurité de la numérisation et du stockage des documents (LIMOS). La numérisation de documents pose deux défis principaux en termes de sécurité. Tout
d’abord comment assurer l’authentification, l’intégrité et la traçabilité des documents numérisés pendant tout le cycle de vie qui s’étend du processus de numérisation jusqu’à l’archivage sécurisé des documents numérisés. Le second défi concerne le développement de modèles physiques de stockage sécurisés et adaptés aux besoins des usagers. L’objectif de ce projet est d’étudier ces deux questions, en liaison avec les cas d’usage pratiques posés par les entreprises intéressées par ce sujet, et d’apporter des solutions adaptées tant sur le plan théorique que pratique.


![]()
- La thèse de doctorat de Matthieu Giraud sur les protocoles sécurisée pour le paradigme MapReduce, dirigée par Pascal Lafourcade et co-encadrée par Radu Ciucanu
- La thèse de doctorat de Kerghan Lecornec sur le Deep Learning Multimodal,dirigée par Vincent Barra
- Le post-doctorat de Ladislav Motak sur l'analyse de documents dématérialisés, dirigée par Marie Izaute
Dans le cadre de ce projet la thèse de Matthieu Giraud a permis de sécuriser les nombreuses et diverses données produites à chaque instant par les usagers et l'IoT. L’analyse de ces données a donné lieu à une nouvelle science nommée "Big Data". Pour traiter du mieux possible ce flux incessant de données, de nouvelles méthodes de calcul ont vu le jour. Les travaux de cette thèse portent sur la cryptographie appliquée au traitement de grands volumes de données, avec comme finalité la protection des données des utilisateurs. En particulier, nous nous intéressons à la sécurisation d’algorithmes utilisant le paradigme de calcul distribué MapReduce pour réaliser un certain nombre de primitives (ou algorithmes) indispensables aux opérations de traitement de données, allant du calcul de métriques de graphes (e.g. PageRank) aux requêtes SQL (i.e. intersection d’ensembles, agrégation, jointure naturelle). Nous traitons dans la première partie de cette thèse de la multiplication de matrices. Nous décrivons d’abord une multiplication matricielle standard et sécurisée pour l’architecture MapReduce qui est basée sur l’utilisation du chiffrement additif de Paillier pour garantir la confidentialité des données. Les algorithmes proposés correspondent à une hypothèse spécifique de sécurité : collusion ou non des nœuds du cluster MapReduce, le modèle général de sécurité étant honnête mais curieux. L’objectif est de protéger la confidentialité de l’une et l’autre matrice, ainsi que le résultat final, et ce pour tous les participants (propriétaires des matrices, nœuds de calcul, utilisateur souhaitant calculer le résultat). D’autre part, nous exploitons également l’algorithme de multiplication de matrices de Strassen-Winograd, dont la complexité asymptotique est O(n^log2(7)) soit environ O(n^2.81) ce qui est une amélioration par rapport à la multiplication matricielle standard. Une nouvelle version de cet algorithme adaptée au paradigme MapReduce est proposée. L’hypothèse de sécurité adoptée ici est limitée à la non-collusion entre le cloud et l’utilisateur final. La version sécurisée utilise comme pour la multiplication standard l’algorithme de chiffrement Paillier. La seconde partie de cette thèse porte sur la protection des données lorsque des opérations d’algèbre relationnelle sont déléguées à un serveur public de cloud qui implémente à nouveau le paradigme MapReduce. En particulier, nous présentons une solution d’intersection sécurisée qui permet à un utilisateur du cloud d’obtenir l’intersection de n > 1 relations appartenant à n propriétaires de données. Dans cette solution, tous les propriétaires de données partagent une clé et un propriétaire de données sélectionné partage une clé avec chacune des clés restantes. Par conséquent, alors que ce propriétaire de données spécifique stocke n clés, les autres propriétaires n’en stockent que deux. Le chiffrement du tuple de relation réelle consiste à combiner l’utilisation d’un chiffrement asymétrique avec une fonction pseudo-aléatoire. Une fois que les données sont stockées dans le cloud, chaque réducteur (Reducer) se voit attribuer une relation particulière. S’il existe n éléments différents, des opérations XOR sont effectuées. La solution proposée reste donc très efficace. Par la suite, nous décrivons les variantes des opérations de regroupement et d’agrégation préservant la confidentialité en termes de performance et de sécurité. Les solutions proposées associent l’utilisation de fonctions pseudo-aléatoires à celle du chiffrement homomorphe pour les opérations COUNT, SUM et AVG et à un chiffrement préservant l’ordre pour les opérations MIN et MAX. Enfin, nous proposons les versions sécurisées de deux protocoles de jointure (cascade et hypercube) adaptées au paradigme MapReduce. Les solutions consistent à utiliser des fonctions pseudo-aléatoires pour effectuer des contrôles d’égalité et ainsi permettre les opérations de jointure lorsque des composants communs sont détectés.
Organismes partenaires :
Financeur : Région Auvergne
Autre financeur : FEDER